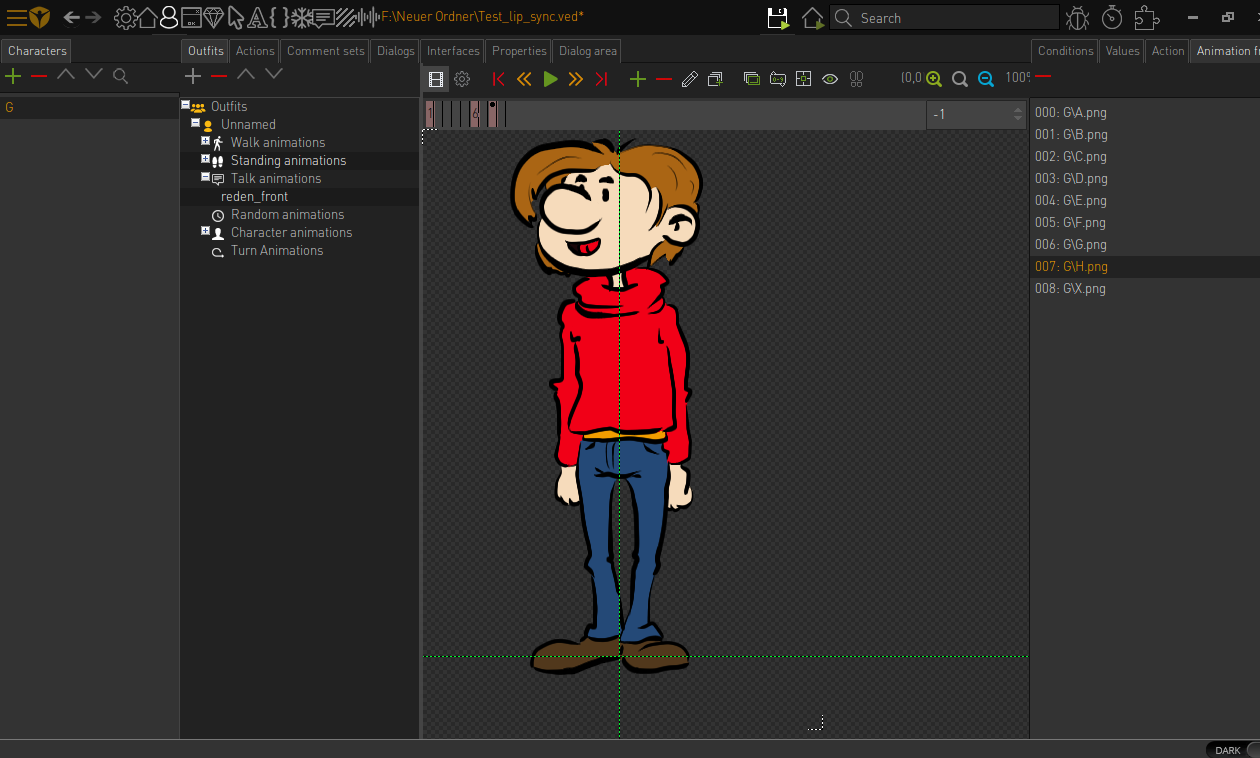
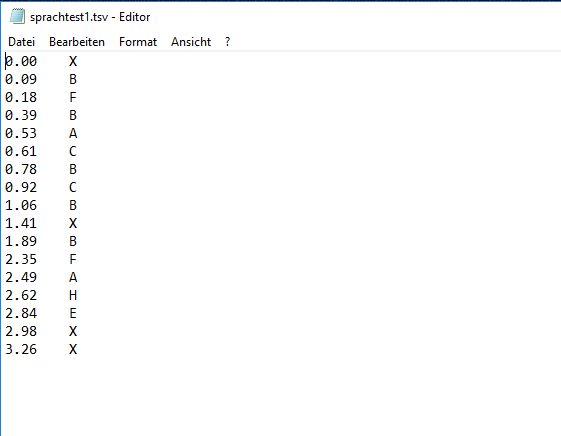
--Translation of Phonemes into Visemes(Mouth Shapes)
PhonemeViseme = {}
PhonemeViseme["PAUSE"] = "PAUSE"
PhonemeViseme["AA"] = "A"
PhonemeViseme["AE"] = "A"
PhonemeViseme["AH"] = "A"
PhonemeViseme["AO"] = "W"
PhonemeViseme["AW"] = "W"
PhonemeViseme["AY"] = "A"
PhonemeViseme["B"] = "M"
PhonemeViseme["CH"] = "U"
PhonemeViseme["D"] = "U"
PhonemeViseme["DH"] = "TH"
PhonemeViseme["EH"] = "A"
PhonemeViseme["ER"] = "O"
PhonemeViseme["EY"] = "A"
PhonemeViseme["F"] = "F"
PhonemeViseme["G"] = "U"
PhonemeViseme["HH"] = "E"
PhonemeViseme["IH"] = "E"
PhonemeViseme["IY"] = "E"
PhonemeViseme["JH"] = "U"
PhonemeViseme["K"] = "U"
PhonemeViseme["L"] = "L"
PhonemeViseme["M"] = "M"
PhonemeViseme["N"] = "TH"
PhonemeViseme["NG"] = "M"
PhonemeViseme["OW"] = "W"
PhonemeViseme["OY"] = "TH"
PhonemeViseme["P"] = "M"
PhonemeViseme["R"] = "R"
PhonemeViseme["S"] = "Y"
PhonemeViseme["SH"] = "Y"
PhonemeViseme["T"] = "Y"
PhonemeViseme["TH"] = "TH"
PhonemeViseme["UH"] = "W"
PhonemeViseme["UW"] = "W"
PhonemeViseme["V"] = "F"
PhonemeViseme["W"] = "W"
PhonemeViseme["Y"] = "U"
PhonemeViseme["Z"] = "U"
PhonemeViseme["ZH"] = "U"
--Visemes (Mouth Shape) - Frame Numbers
VisemeFrame = {}
VisemeFrame["BLANK"] = 1
VisemeFrame["PAUSE"] = 1
VisemeFrame["A"] = 2
VisemeFrame["E"] = 3
VisemeFrame["F"] = 4
VisemeFrame["L"] = 5
VisemeFrame["M"] = 6
VisemeFrame["O"] = 7
VisemeFrame["R"] = 8
VisemeFrame["TH"] = 9
VisemeFrame["U"] = 10
VisemeFrame["W"] = 11
SpeechPhonemes = {}
SpeechPhonemes["A"] = { "AH" }
SpeechPhonemes["AGAIN"] = { "AH","G","EH","N" }
SpeechPhonemes["AM"] = { "AE","M" }
SpeechPhonemes["AN"] = { "AE","N" }
SpeechPhonemes["ANOTHER"] = { "AH","N","AH","DH","ER" }
SpeechPhonemes["ARE"] = { "AA","R" }
SpeechPhonemes["AWAY"] = { "AH","W","EY" }
SpeechPhonemes["BELIEVE"] = { "B","IH","L","IY","V" }
SpeechPhonemes["BONES"] = { "B","OW","N","Z" }
SpeechPhonemes["BOOKCASE"] = { "B","UH","K","K","EY","S" }
SpeechPhonemes["BUT"] = { "B","AH","T" }
SpeechPhonemes["BUTTONS"] = { "B","AH","T","AH","N","Z" }
SpeechPhonemes["BYE"] = { "B","AY" }
...